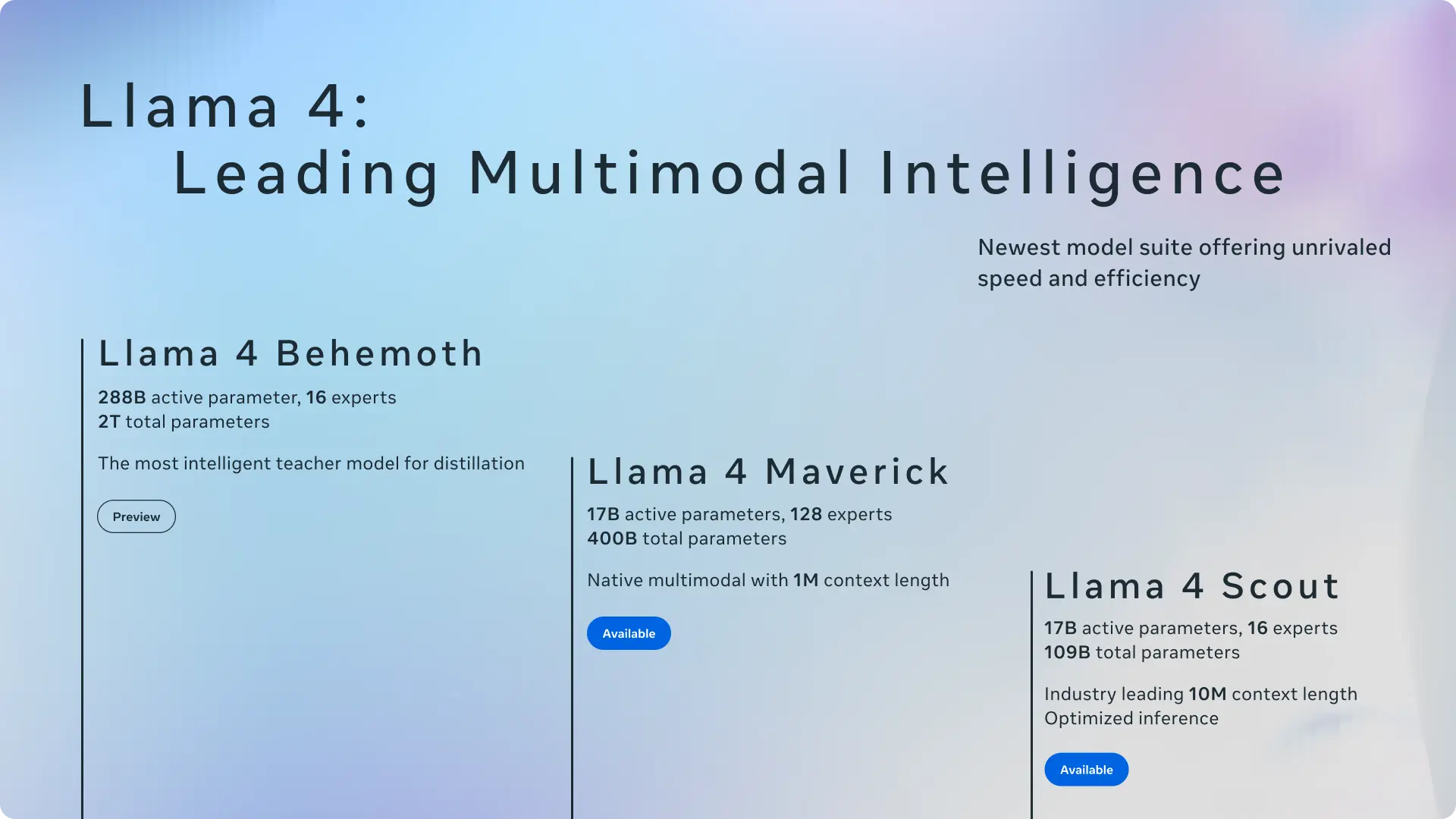
Meta Dituduh ‘Curang’ dalam Uji Benchmark AI: Era Baru Persaingan?
Meta, raksasa teknologi di balik Facebook dan Instagram, baru-baru ini dituduh melakukan kecurangan dalam uji benchmark AI. Tuduhan ini muncul setelah Meta merilis dua model AI baru berdasarkan Llama 4, yaitu Scout dan Maverick.
Maverick, yang digadang-gadang sebagai pesaing efisien bagi model seperti GPT-4o dari OpenAI, mencuri perhatian karena skor ELO yang fantastis di LMArena, sebuah platform open-source untuk menguji kemampuan model bahasa. Skor Maverick bahkan sempat mengungguli GPT-4o!
Kecurigaan dan Pengakuan Meta
Namun, kejanggalan mulai tercium. Para pengamat AI menemukan bahwa model Maverick yang diuji coba oleh Meta berbeda dari versi yang tersedia untuk publik. Meta mengakui bahwa model yang diuji telah diprogram untuk lebih ‘cerewet’ atau persuasif, sehingga mampu ‘membujuk’ benchmark untuk memberikan skor yang lebih tinggi.
Reaksi LMArena dan Implikasi ke Depan
LMArena tidak senang dengan taktik ini. Mereka menyatakan bahwa interpretasi Meta terhadap kebijakan mereka tidak sesuai dengan yang diharapkan dari penyedia model. LMArena berencana memperbarui kebijakan leaderboard untuk memastikan evaluasi yang adil dan dapat direproduksi di masa depan.
Era Baru Persaingan dan ‘Kecurangan’ dalam Benchmark?
Insiden ini menyoroti betapa pentingnya benchmark dalam persaingan di dunia AI. Perusahaan-perusahaan AI berlomba-lomba untuk menunjukkan keunggulan model mereka, dan terkadang, mereka tergoda untuk melakukan ‘kecurangan’ demi mendapatkan skor yang lebih baik.
Apakah ini pertanda era baru persaingan yang lebih ketat, di mana perusahaan-perusahaan AI akan terus mencari cara untuk ‘memanipulasi’ benchmark? Hanya waktu yang bisa menjawab. Namun, satu hal yang pasti: pengguna akan semakin kritis dalam menilai kemampuan model AI, tidak hanya berdasarkan skor benchmark, tetapi juga berdasarkan pengalaman penggunaan yang sebenarnya.
Seiring dengan semakin matangnya model AI dan menjelma menjadi produk yang dihadapi konsumen, kita akan melihat lebih banyak pameran benchmark. Kita juga akan melihat antarmuka pengguna mulai berubah, toko-toko konyol seperti bagian Jelajahi GPT dari aplikasi ChatGPT menjadi lebih umum. Perusahaan-perusahaan ini harus membuktikan mengapa model mereka adalah model terbaik dan benchmark saja tidak akan melakukan itu. Bukan ketika bot yang cerewet dapat mengelabui sistem dengan begitu mudah.











Leave a Reply